OpenMP¶
Introduction¶
OpenMP (Open Multi-Processing) is an Application Program Interface (API) that supports Fortran and C/C++. OpenMP is designed for multi-processor (or multi-core), shared memory machines. The underlying architecture can be UMA or NUMA shared memory.
This section gives a quick introduction to OpenMP with Fortran example codes. For more information refer to www.openmp.org. In particular, you may find here and here useful.
The Fortran codes for the examples in this section can be found in the course repository in directory “OpenMP”.
Basic idea: fork-join model¶
OpenMP accomplishes parallelism through the use of threads. A thread of execution is the smallest unit of processing that can be scheduled by an operating system. The programmer controls parallelization using fork-joint model of parallel execution:
- All OpenMP programs begin as a single process, known as the master thread. The Master thred executes until a parallel region construct is encountered.
- The sequantial execution branches off (or forks) in parallel at designated points in the program, and a number of parallel threads execute on a number of processors/cores simultaneously. Typically, the number of threads matches the number of machine processors/cores. Rule of thumb: one thread per processor/core.
- After threads execute, they merge (or join) at a subsequent point and resume sequential execution.
As an example, the figure below (taken from Wikipedia) is a schematic representation of a parallel code, where three regions of the code (i.e. parallel tasks) permit parallel execution of a number of threads.
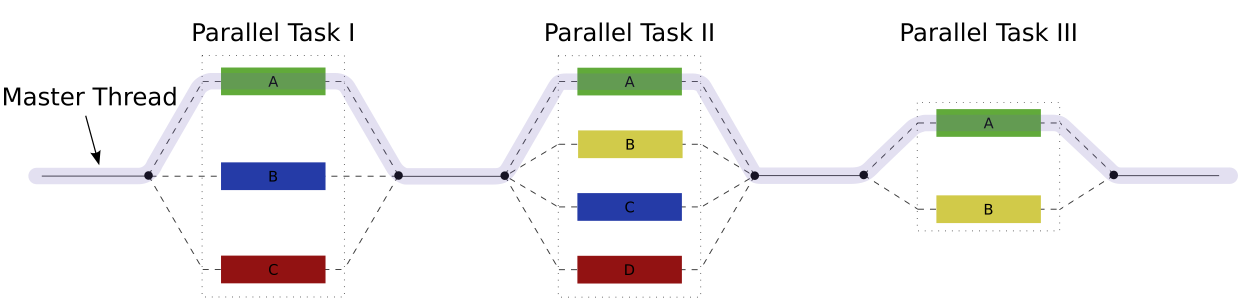
Note that threads may need to synchronize if there is dependency. The programmer is responsible for synchronizing input and outputs. See below.
General recepie¶
OpenMP is an explicit (not automatic) programming model, offering you (the programmer) full control over parallelization.
First, given a serial code, you decide where to fork, where to join, and how to split a parallel region into a number of tasks. You may also need to synchronize threads.
Next, you convert the serial code into a parallel code in such a way that it can still run in serial mode. This is done by employing the three components of OpenMP (see OpenMP components below) and using two directive sentinels:
- !$OMP
- !$
When a non-OpenMP compiler encounters these lines, it will treat those
lines as comments. However, when an OpenMP compiler encounters these
lines, it will compile the directives and statements in those
lines. To run with an OpenMP compiler, you just need to use
gfortran with the flag -fopenmp.
!$OMPis followed by an OpenMP directive.Example:
!$OMP parallel default(shared) private(x,pi)!$can be followed by ordinary Fortran statements to enable conditional compiling.Example:
!$ print *, "This line will be compiled with -fopenmp flag"
OpenMP components¶
OpenMP consists of three components:
- Compiler directives
- Runtime library routines
- Environment variables
We will briefly discuss the first two components.
1. Compiler directives¶
OpenMP compiler directives are used for various purposes, such as (1) generating a parallel region; (2) dividing blocks of code among threads; (3) distributing loop iterations between threads; and (4) synchronization of work among threads. A parallel region is a block of code that will be executed by multiple threads. This is the fundamental OpenMP parallel construct.
They have the syntax: sentinel directive-name [clause1] [clause2] ...
The sentinel is !$OMP, followed by a white space and the name of a valid OpenMP directive. Clauses are optional and can be in any order. Note that some clauses will not be accepted by some directives.
Important directives include:
- PARALLEL: duplicates the code in the parallel region on all threads, so that each thread works independently doing all instructions in the region
- DO: shares iterations of a loop in parallel across the team
- PARALLEL DO: takes advantage of both PARALLEL and DO
- SECTIONS: breaks work into separate sections, each executed once by a thread in the team
- SINGLE: serializes a section of code, so that the section is executed by only one thread in the team.
- Synchronization directives: Sometimes, you need to synchronize the
work among threads. This can be done by the following
directives. Note that the synchronization directives do not accept cluses.
- MASTER
- CRITICAL
- BARRIER
Important clauses include:
if (a scalar logical expression)
supported by PARALLEL, PARALLEL DO
private (list)
supported by PARALLEL, DO, PARALLEL DO, SECTIONS, SINGLE
shared (list)
supported by PARALLEL, DO, PARALLEL DO
default (private | shared | firstprivate)
supported by PARALLEL, PARALLEL DO
firstprivate (list)
supported by PARALLEL, DO, PARALLEL DO, SECTIONS, SINGLE
reduction (operator : list)
supported by PARALLEL, DO, PARALLEL DO, SECTIONS
schedule (type, chunk)
supported by DO, PARALLEL DO
2. Runtime library routines¶
Library routines are used for various purposes, such as (1) setting
and querying the number of threads; (2) querying a thread’s unique
identifier (thread ID); and (3) querying wall clock time. You need to
include !$ use omp_lib in your code to have access to these routines.
Important library routines include:
omp_set_num_threads
This will set the number of threads that will be used in the next parallel region. This routine can only be called from the serioal portions of code.
omp_get_num_threads
This will return the number of threads that are currently in the team executing the parallel region from which it is called.
omp_get_thread_num
This will return the thread number of the thread within the team
omp_get_wtime
This will return the elapsed time (in seconds), as a double-precision floating point value, since some point in the past. In order to obtain the elapsed time for a block of code, this function is used in pairs with the value of the first call subtracted from the value of the second call.
Among the above, the first one is a subroutine, and the other three are functions. Note that they all need to come after !$.
Example 1¶
1 2 3 4 5 6 7 8 9 10 11 12 13 | program OMP1
!$ use omp_lib
integer :: tid, nthreads
!$ call omp_set_num_threads(4)
!$omp parallel private(tid)
!$ tid = omp_get_thread_num()
!$ print *, 'This is thread no. ', tid
!$ if (tid .eq. 0) then
!$ nthreads = omp_get_num_threads()
!$ print *, 'Total number of threads = ', nthreads
!$ end if
!$omp end parallel
end program OMP1
|
Line 2: need to use the OpenMP module to have access to subroutines and functions.
Line 4: OpenMP library subroutine is used to set the number of threads to 4.
The block between lines 5 and 12 is the parallel region and will be executed in parallel by multiple threads (here 4).
Every thread executes all code enclosed in the parallel region. Each thread works independently doing all instructions in the block.
Line 5: the thread number (tid) must be private. Each thread must have its own version of the tid variable, since each thread has its own number.
Line 6: OpenMP library function is used to obtain thread identifiers. This call must be inside the parallel region
Line 8-11: only master thread (which has id zero in the team) does this.
Line 9: OpenMP library function is used to obtain the total number of threads.
To compile and run:
$ gfortran -fopenmp -c OMP1.f90 $ gfortran -fopenmp OMP1.o -o OMP1.x $ ./OMP1.x
This may give the following output:
This is thread no. 3 This is thread no. 2 This is thread no. 0 This is thread no. 1 Total number of threads = 4
The order of executaion will not be guaranteed.
You may also compile without OpenMP flag. In this case the parallel block will not be executed.
Example 2¶
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | program OMP2
!$ use omp_lib
implicit none
integer :: tid,i
real(kind = 8) :: sum
!$ call omp_set_num_threads(4)
sum = 0.d0
tid = 1
!$omp parallel private(tid,i,sum)
!$ tid = omp_get_thread_num()
do i = 1,tid
sum = sum + 1.d0
end do
write(*,*) "I am processor no.", tid, " and my sum is ", sum
!$omp end parallel
end program OMP2
|
Each processor with ID number N (here N=0, 1, 2, 3) will compute sum = 1+2+ … +N.
Line 9: the variables tid, i, and sum are declared private because each processor must have its own version of these veriables.
Compiling with -fopenmp, we may get the following output:
I am processor no. 3 and my sum is 3.0000000000000000 I am processor no. 1 and my sum is 1.0000000000000000 I am processor no. 0 and my sum is 6.9532229757727091E-310 I am processor no. 2 and my sum is 2.0000000000000000
If you compile without -fopenmp, you would get:
I am processor no. 1 and my sum is 1.0000000000000000
Example 3¶
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 | program OMP3
!$ use omp_lib
integer i, chunk
integer, parameter :: n=10
real a(n), b(n), c(n)
do i=1,n
a(i) = i * 1.0
b(i) = a(i)
enddo
chunk = 2
!$omp parallel shared(a,b,c,chunk) private(i)
!$omp do schedule(dynamic,chunk)
do i=1,n
c(i) = a(i) + b(i)
enddo
!$omp end do
!$omp end parallel
print *, c
end program OMP3
|
- The iterations of the loop will be distributed dynamically in CHUNK sized pieces.
- Arrays a, b, c, and variable n will be shared by all threads, while variable i will be private to each thread.
Example 4¶
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 | program OMP4
!$ use omp_lib
integer i, chunk
integer, parameter :: n=10
real a(n), b(n), c(n)
do i=1,n
a(i) = i * 1.0
b(i) = a(i)
enddo
chunk = 2
!$omp parallel do shared(a,b,c,chunk) private(i) schedule(dynamic,chunk)
do i=1,n
c(i) = a(i) + b(i)
enddo
!$omp end parallel do
print *, c
end program OMP4
|
- This is the same as Example 3.
Example 5¶
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 | program OMP5
!$ use omp_lib
INTEGER :: N, I
PARAMETER (N=1000)
REAL :: A(N), B(N), C(N), D(N)
DO I = 1, N
A(I) = I * 1.5
B(I) = I + 22.35
ENDDO
!$OMP PARALLEL SHARED(A,B,C,D), PRIVATE(I)
!$OMP SECTIONS
!$OMP SECTION
DO I = 1, N
C(I) = A(I) + B(I)
ENDDO
!$OMP SECTION
DO I = 1, N
D(I) = A(I) * B(I)
ENDDO
!$OMP END SECTIONS
!$OMP END PARALLEL
end program OMP5
|
Example 6¶
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 | program OMP6
!$ use omp_lib
implicit none
integer :: tid,nthreads,i
real(kind = 8) :: sum
!$ call omp_set_num_threads(4)
sum = 0.d0
tid = 1
!$omp parallel private(tid,i,sum)
!$ tid = omp_get_thread_num()
do i = 1,tid
sum = sum + 1.d0
end do
write(*,*) "I am processor no.", tid, " and my sum is ", sum
!$omp single
!$ nthreads = omp_get_num_threads()
!$ print *, 'Total number of threads = ', nthreads
!$omp end single
!$omp end parallel
end program OMP6
|
- Single directive is useful for instance for initializing or printing out a shared variable.
- You can also use
!$omp masterinstead of!$omp singlein line 15 to force execution by the master thread. In general, the user must not make any assumptions as to which thread will execute a single region. - Only one thread will execute lines 16-17. All other threads will
skip the single region and stop at the end of the single construct
until all threads in the team have reached that point. If other
threads can proceed without waiting for the single thread executing
the single region, a nowait clause can be specified. For this you
would need to replace line 18
by
!$omp end single nowait.
Example 7 (Buggy code)¶
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 | program OMP7 !Buggy code!!
!$ use omp_lib
integer n, chunk, i
parameter (n=100)
real :: a(N), b(N), result
do i=1,n
a(i) = i * 1.0
b(i) = i * 2.0
enddo
result=0.0
chunk=10
!$OMP PARALLEL DO DEFAULT(SHARED) PRIVATE(I) SCHEDULE(STATIC,CHUNK)
do i = 1,n
result = result + (a(i) * b(i))
enddo
!$OMP END PARALLEL DO
print *, 'x . y = ', result
end program OMP7
|
Example 8 (Correct code)¶
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 | program OMP8 !Correct version
!$ use omp_lib
integer n, chunk, i
parameter (n=100)
real :: a(N), b(N), result
do i=1,n
a(i) = i * 1.0
b(i) = i * 2.0
enddo
result=0.0
chunk=10
!$OMP PARALLEL DO DEFAULT(SHARED) PRIVATE(I) SCHEDULE(STATIC,CHUNK) REDUCTION(+:RESULT)
do i = 1,n
result = result + (a(i) * b(i))
enddo
!$OMP END PARALLEL DO
print *, 'x . y = ', result
end program OMP8
|
- Iterations of the parallel loop will be distributed in equal sized blocks to each thread in the team: SCHEDULE (static, chunk)
- REDUCTION(+:result) will create a private copy of result and initialize it (to zero) for each thread. At the end of the parallel loop, all threads will add their values of result to update the master thread’s global copy.
Example 9 (Buggy code)¶
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 | program OMP9 !BUGGY code!!
!$ use omp_lib
IMPLICIT NONE
integer, parameter :: n = 100000
integer :: i
real(kind = 8) :: sum,h,x(0:n),f(0:n)
!$ call OMP_set_num_threads(8)
h = 2.d0/dble(n)
!$OMP PARALLEL DO PRIVATE(i)
do i = 0,n
x(i) = -1.d0+dble(i)*h
f(i) = 2.d0*x(i)
end do
!$OMP END PARALLEL DO
sum = 0.d0
!$OMP PARALLEL DO PRIVATE(i)
do i = 0,n-1
sum = sum + h*f(i)
end do
!$OMP END PARALLEL DO
write(*,*) "The integral is ", sum
end program OMP9
|
The code is buggy! Try to run this program a couple of times:
motamed$ ./OMP10.x The integral is -3.9999999999998405E-003 motamed$ ./OMP10.x The integral is -6.6599999999999770E-002 motamed$ ./OMP10.x The integral is -0.12253599999999992 motamed$ ./OMP10.x The integral is -4.6559999999999893E-002 motamed$ ./OMP10.x The integral is -0.10002399999999984 motamed$ ./OMP10.x The integral is -4.0527999999999897E-002
Example 10 (Correct code)¶
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 | program OMP10 !Correct version
!$ use omp_lib
IMPLICIT NONE
integer, parameter :: n = 100000
integer :: i
real(kind = 8) :: sum,h,x(0:n),f(0:n)
!$ call OMP_set_num_threads(8)
h = 2.d0/dble(n)
!$OMP PARALLEL DO PRIVATE(i)
do i = 0,n
x(i) = -1.d0+dble(i)*h
f(i) = 2.d0*x(i)
end do
!$OMP END PARALLEL DO
sum = 0.d0
!$OMP PARALLEL DO PRIVATE(i) REDUCTION(+:SUM)
do i = 0,n-1
sum = sum + h*f(i)
end do
!$OMP END PARALLEL DO
write(*,*) "The integral is ", sum
end program OMP10
|
Now run this program a couple of times:
motamed$ ./OMP11.x The integral is -3.9999999999706937E-005 motamed$ ./OMP11.x The integral is -3.9999999999706937E-005 motamed$ ./OMP11.x The integral is -3.9999999999651425E-005 motamed$ ./OMP11.x The integral is -3.9999999999595914E-005
Example 11¶
This example show how to measure the wallclock time using both Fortran subroutine system_clock and the OpenMP library routine omp_get_wtime.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 | program OMP11 !timing code
!$ use omp_lib
IMPLICIT NONE
integer, parameter :: n = 100000
integer :: i,j
integer(kind=8) :: t0, t1, clock_rate
real(kind = 8) :: sum,h,x(0:n),f(0:n),dt
!$ real(kind=8) :: omp_t0, omp_t1, omp_dt
!$ call OMP_set_num_threads(8)
h = 2.d0/dble(n)
!$ omp_t0=omp_get_wtime()
call system_clock(t0)
do j=1,1000 !Run this 1000 times to get a few seconds of CPU time
!$OMP PARALLEL DO PRIVATE(i)
do i = 0,n
x(i) = -1.d0+dble(i)*h
f(i) = 2.d0*x(i)
end do
!$OMP END PARALLEL DO
sum = 0.d0
!$OMP PARALLEL DO PRIVATE(i) REDUCTION(+:SUM)
do i = 0,n-1
sum = sum + h*f(i)
end do
!$OMP END PARALLEL DO
enddo
!$ omp_t1=omp_get_wtime() !omp_t1 needs to be declared as real
!$ omp_dt=omp_t1-omp_t0
call system_clock(t1,clock_rate)
dt = float(t1 - t0) / float(clock_rate)
write(*,*) "The integral is ", sum
!$ print *, "OMP elapsed time = ", omp_dt, "sec."
print *, "Fortran elapsed time =", dt, "sec."
end program OMP11
|
The output with -fopenmp flag (on my 3GHz dual-core Intel Core i7 Apple MacBook) is:
The integral is -3.9999999999651425E-005 OMP elapsed time = 0.41845393180847168 sec. Fortran elapsed time = 0.41844800114631653 sec.
And without -fopenmp (with only one processor):
The integral is -4.0000000000106370E-005 Fortran elapsed time = 1.0169110298156738 sec.